Preamble
There are many interesting questions in Anoma that have gone answered. Below is a small collection of them mainly focusing on long term burning quests I need answers to to better outline the long term system of Anoma
Terminology
- Message Send :: To invoke a method on an object.
- Method :: An operation on an object. Methods are themselves objects
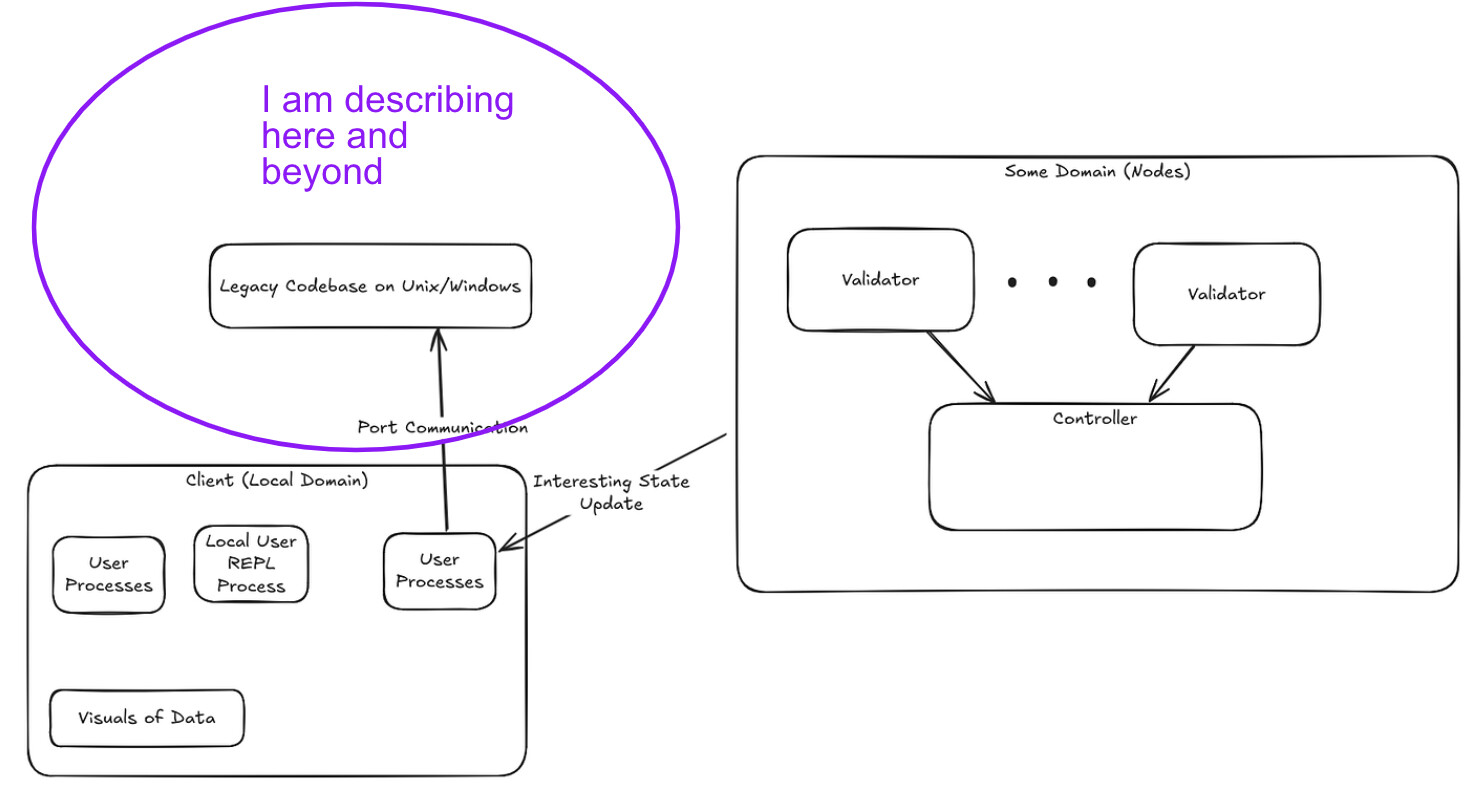
- Chambers :: Private controller domain
- Court :: Shared controller domain between many parties
- Domain :: Either the court or chambers
- Have Control :: To be the dictator of a domain and can force changes
at will - CLOS :: Common Lisp Object System
- Erlang :: The Erlang programming language™
- Upgrade :: To change code from one state to another
- Engine :: An Actor
- Overload :: The ability to change the behaviour of a method in some
manner
Problems we need to think/specify
- What times of computation are there?
- What is the object structure of courts and chambers?
- How do structures get upgraded within a controlled domain? Do we
steal with CLOS does or what erlang does? How do we initiate
updates for domains we don’t control?- If we have a way to initiating code updating on say other
courts, does this work via message send? - Can we initiate consensus upgrades this way?
- If we have a way to initiating code updating on say other
- How does consensus upgrades work, when does the new code take
affect? Is this an overloadable method on the court? - What is the boundary between court and chambers?
- What is the interface for engines in system
- What properties do we wish to gain out of them?
- How do we synthesize event based programming with them? Do we
steal urbit’s design a bit?
- Can we realize our long lived actors as objects? What about them do
we wish to prioritize? - How do we realize an OO protocol ontop of the RM model
- My first stab at it was here:
On the Will to Adapt: A Resource story - If everything as a resource computation, then =(+ 1 1)= is a
transaction, where we get back the resource/object =2=. In this,
do we just return all new committed objects!? - Do we make the model declarative? If so, then do we get solvers
for free by unification!?!? Further, should we go full in on the
declarative OO model?
- My first stab at it was here:
- Can we realize Identities in system, what is the interface like?
- On Identities: Or how I learned to stop worrying and love Anoma
- We know it’s not an engine.
- What is the flow for the user?
- Do we do RM transaction processing in the chambers? How does it
relate to our current work? How does it relate to our Object story? - What is the boundary between Objects as resources, and the
immutable data in storage?- I got a partial answer from Ray before, when we scry the data
since we give the type we inherently wrap it in an
object/resource interface. - Another method could be we interpret raw data as an object in a
wrapper.
- I got a partial answer from Ray before, when we scry the data
- How do we ensure the code that each court runs is the same!? How
can we trust the other parties to run exactly the same code?- I’d imagine it’d be a pain to maintain forks if there are
frequent upgrades but if there is money on a line I’d imagine
this would be an issue.
- I’d imagine it’d be a pain to maintain forks if there are
- What are the major flows of the versions?
- Is every engine encompassed in some kind of flow?
- Namely is the user flow and all components thought of for a
particular release.
- What is interop like within the various resource machines?
- This is a very broad question
- How does indexing work for shielded
- I believe xuyang did research good to get this written up
- Can we define what an intent is
- I like the idea of coalgebras but it should probably be defined
in the specs, I think this may have interesting synergy if we go
in a declarative model
- I like the idea of coalgebras but it should probably be defined