Thanks for clarifying. This and your talk together have solidified the system at a lower level.
My updated understanding:
- The Anoma client has a runtime where objects, which include engines and resources, can be referenced.
- At this runtime level, the engine is the system performing ‘indexing’ of data from controllers, and long-standing processes.
- At the client level, Anoma has a GUI to allow users to modify engines and things, and this is where the Glamorous toolkit comes in.
I have been talking and building around everything on the other side of the Anoma client, in the ‘outer world’ at the application level.
In other words, I am answering the question “What happens when data comes and goes from the FFI into the rest of the world?” and “How do we make these things work together better?”
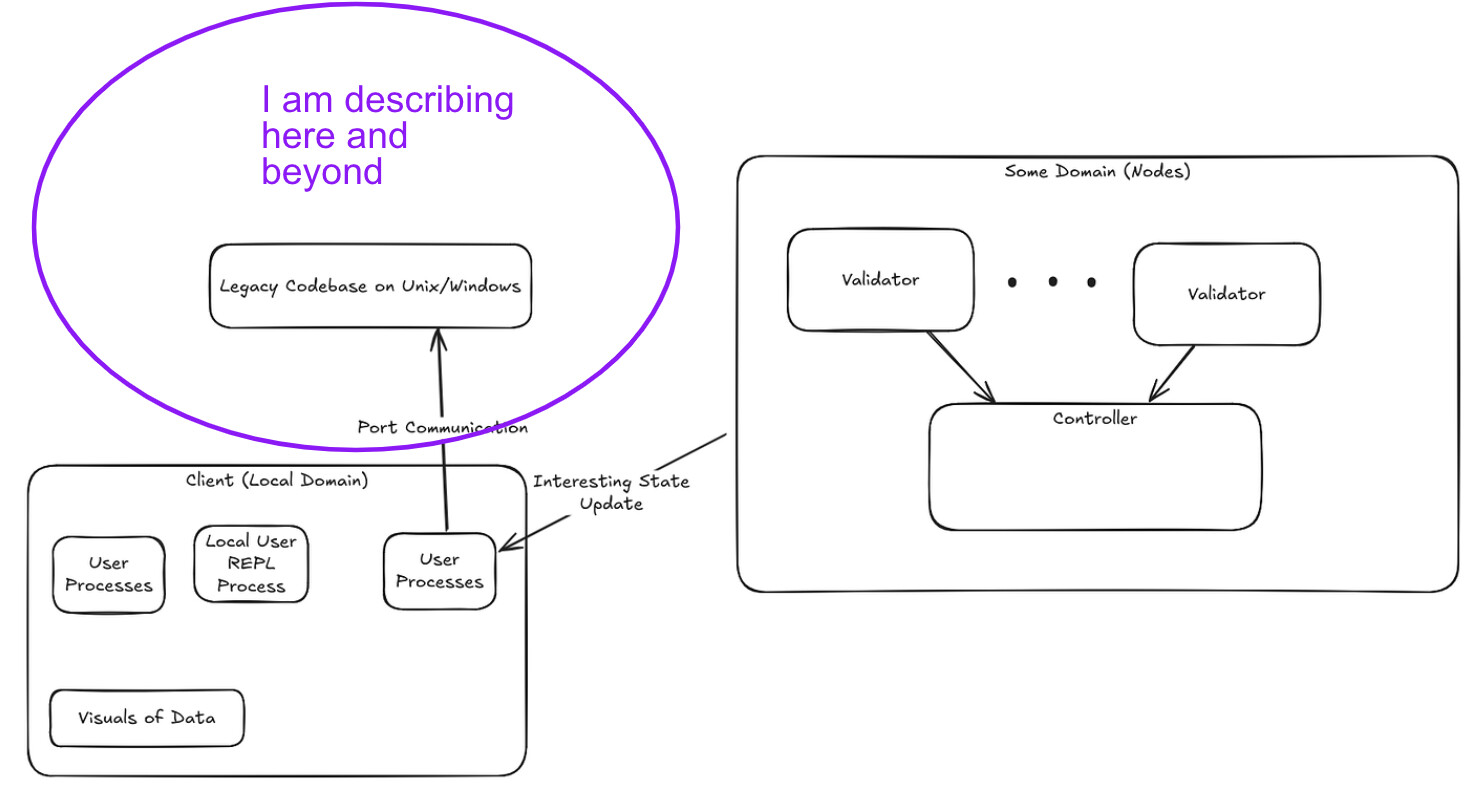
Annotating over your image but I see it more like a threshold than a bubble.
A developer may want to define a process where some outer world event, like I/O in the app, triggers a change to the controller in their domain.
The easiest thing to do is to write some logic that runs on a Windows/Unix system that just calls the FFI as needed, but this goes into my previous responses and broader motivation. This gets hard to reason about, build, and get visibility into as complexity increases.
This is getting abstract so I have added an example below. I understand the great breakthroughs of Anoma, and that there is a way to write this as a resource with transactions that alter the state.
As the application increases in complexity, I believe this painpoint becomes glaring and the tools I am building really shine.
Vanilla: Resources and Resource Logic
With resources, you can write resource logic to define the state of the system and the conditions in which state changes.
If I had a counter resource, I could create resource logic that increments or decrements this counter.
The painpoint
What happens when some state isn’t known to the system at the time of creation (And is entered by the user, or accessed via API)?
Ex: I am building a food ordering application where the state and state changes are dependent on customized input from the user placing the order and the actions of the restaurant receiving the order.
Yes, I could create resources that reflect all of the menu items, including the permutations a person could change, and I could solve for all of the possible state changes through a really tight set of resource logic, but that gets hard really fast.
What happens when it becomes computationally expensive to write transactions for every state change?
Ex: In this food ordering service, I would make every food option on the menu a resource, and have a parent resource or a projection function that groups all of the resources in a given order. But this is a lot of compute and complexity for many orders in a day.
This does not include questions like what happens with the restaurant rejects an order? How do we group the food objects of an order? And all the non-deterministic things that can occur in this system.
Solution: Concordance - Workflow Orchestration
Developers need the ability to build workflows that are reliable and interoperable with the blockchain, even when state is segmented or recieved from sources outside the local domain.
I have been building Concordance, a workflow orchestration platform (similar to Temporal) but for Web3.

In our example, developers can define the entire order state within one order object, and allow the user to edit that order object with the food and customizations.
When the order is confirmed by the user, the object and its metadata is serialized and sent through as a transaction to Anoma. Once in the local domain, proof validation and underlying resource updates happen as designed within the Anoma system.
Developers write logic based on the object, and the possible states of that object. In this example, we would have an object schema:
const order = new object.resource.protobuf()
order {
order_num: int,
date: date,
items: [array],
}
and state mappings
const ORDER_TRANSITIONS = {
[ORDER_STATES.INITIATED]: [ORDER_STATES.CONFIRMED, ORDER_STATES.TIMED_OUT],
[ORDER_STATES.CONFIRMED]: [ORDER_STATES.COOKING, ORDER_STATES.CANCELED],
[ORDER_STATES.COOKING]: [ORDER_STATES.READY, ORDER_STATES.CANCELED],
[ORDER_STATES.READY]: [ORDER_STATES.RECEIVED, ORDER_STATES.ABANDONED],
[ORDER_STATES.RECEIVED]: [ORDER_STATES.COMPLETE],
[ORDER_STATES.TIMED_OUT]: [], // Terminal state
[ORDER_STATES.CANCELED]: [], // Terminal state
[ORDER_STATES.ABANDONED]: [], // Terminal state
[ORDER_STATES.COMPLETE]: [] // Terminal state
};
Developers write code that feels like Redux, and Concordance does the orchestration for the system, breaking down actions to state and triaging what compute is performed where, accounting for verification at each step of the process. (Concordance does other cool orchestration stuff like idempotency and caching, etc)
Developers can write validation for each discrete state, and other ‘business logic’ that may only apply at a discrete state/after an action occurs. e.g. When a user clicks a button, an API is called, and the results of the API can determine how state changes.

The entire application is structured by state. Under the hood, the compute segmentation still occurs. Some compute is done on a windows machine, be it in the browser or server-side compute, and some compute on Anoma, but this segmentation is abstracted away, allowing the developer to focus purely on objects and their respective state.
Because Anoma manages so much of the orchestration that occurs in blockchain-related compute, it made the most sense to just drop this on top of Anoma architecture.
This allows for predictability at the application level because to the developer, there is one source of truth for state, even if some of that state exists within the controller. Concordance ‘guarantees’ the application executes in these discrete steps.
I hope this adds clarity to the questions I have been asking, and my meaning of ‘object abstraction’ in the context of our conversations.
Object abstraction as you describe works in the local domain to allow developers to modify the Anoma client.
Object abstraction as I describe works at the application level, and allows developers to define application workflows. (It appears I need to find better language for this, I do have a hard time explaining this tech to folks in a succinct way.)