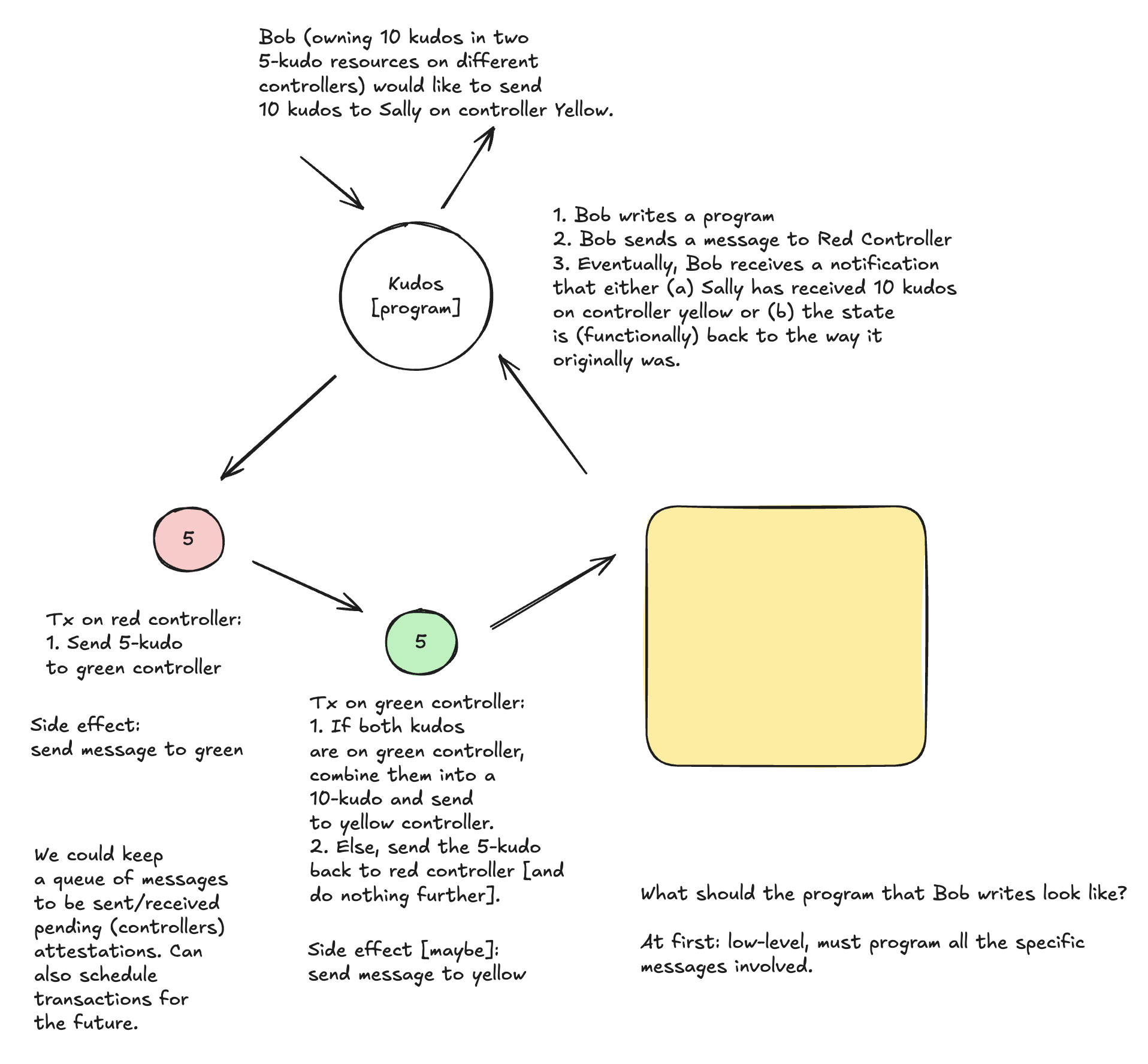
In general, we want to gradually reify entities in the distributed system as objects in the AVM, so that eventually we can describe the AVM transition function purely in terms of messages sent between objects (and potential user input) and have this correspond to interactions in the actual distributed system, roughly like so:
The objective of this post is to outline some specific object interfaces for the local domain, solver, and controller, such that we can talk about AVM programs which interact with those three entities.
Local domain
A particular program, from the perspective of the program author, will always begin execution in the local domain (since that is the only location/object to which the program author can directly send messages). From the perspective of a program running within it, the local domain should provide the ability to read and write local storage (ref: prior specs) and to utilize locally-known identities (we’ve worked out much of this before). The local domain should also provide the ability for a program to send messages to external Anoma instances (e.g. solvers, controllers), which will be processed by the local domain’s networking subsystem (and e.g. route correctly based on known external identity → physical address mappings).
Methods enumerated
Read, write, and delete from local storage (roughly this API).
Decrypt data (here) and generate commitments (here) using identities tracked by the local domain. If necessary, create new identities and/or delete them (here).
Send and receive messages to and from external nodes (here), in both call/response (~ object) and broadcast-only / receive-only (asynchronous) modes.
Solver
A particular program running on the local domain should be able to send a message to a solver containing a partial transaction with unsatisfied constraints that the solver can try to find a match for, along with any metadata necessary for the solver to search efficiently. In this simple model, the solver will simply try to match and directly message the controller if successful, or otherwise return a failure (after some period of time).
Methods enumerated
Send partial transaction, receiving a response (after some time) indicating either success (with transaction details) or failure to find a match.
Controller
A particular program running on the local domain should be able to query a controller for information about any resources controlled by that controller (commitments, nullifiers, resource-linked data, etc.) and to submit a transaction to the controller.
Methods enumerated
Query controller state, receiving the appropriate data in response [read transaction].
a. At a high level this is the scry API.
b. At a lower level this must be expressed in terms of queries about commitments, nullifiers, indices (state architecture ART), resource-linked data, etc.
Submit transaction (function)s, receiving a response.
a. This can be a TransactionFunction to start.
For simplicity, we can start here with just specific messages – the ones supported by the solver and controller – where the program just specifies the external identity in question. The calls should be asynchronous, but we should support an expect_response with a timeout (which the program must then handle in some appropriate manner).
Hopefully, this can be similar to a potential cross-controller-object messaging API in the future.
Some questions about local domain program design that I’m mulling over:
Do we want transactionality for programs running in the local domain, and of what sort? We should in principle be able to have transactional updates for any local storage (including identities), but obviously not any external (network) calls.
How should caching be expressed? The cache (of remotely-managed objects) should definitely be shared by all programs running in the local domain (so it shouldn’t be separately implemented per-program), although this should also be achievable just with standard use of shared local storage. We’ll need some way to “label” queries with consistency requirements (cache policies) in order to determine what sort of checks we need to do before returning a result based purely on the local cache. We’ll also need some policies as to how the local cache should be expunged (probably just simple LRU is fine as a start), and whether sync should happen in the background (this should probably be expressed as part of a local domain program, but with some standard libraries).
For the local domain we should probably have an “AVM runtime” which does not use the resource machine, which is overkill for purely local state updates which do not need Merkleization, separate proofs, etc.
We could, however, consider a transparent resource machine on a “local controller” – useful for e.g. syncing “local drafts” between devices – but from the perspective of the local domain this should not be much different than any other controller.
Perhaps for this purpose it will soon be worth defining a “local AVM operational semantics” which defines how programs must be interpreted. This operational semantics would then (a) be implemented (somehow, details up to engineering) in the local domain and (b) match (let’s hope) the semantics of executing AVM programs which are compiled to the resource machine. It should have a concept of transaction (including foreign/async calls).
What should this operational semantics look like?
Within a particular domain, “big steps” are transactional – programs either fully complete or have no effect – and transactions are serializable. Execution of a transaction entails appending all messages to the relevant object histories. Transactions may also append to queues for messages (programs?) to be sent elsewhere [and in the future objects to be sent elsewhere, implemented w/controllers, but let’s save that for now].
“Small steps” should be roughly processing of all causally independent messages.
Across domains, messages arrive atomically and in order, but otherwise with unpredictable delays (that we may make assumptions about in practice).